Shift Media has merged with EditShare! Learn more here.




Share



Product
Just Ship It Already: How Wiredrive Took Deploys from Hours to Minutes
One of our technology principles is to aggressively retire or replace unnecessary complexity so we can focus on the necessary complexity [that moves the business]. Our “necessary complexity”, in this case, is our desire to rebuild the product delivery (or growth) engine for our customers. With that as our decision making background, we decided to assess our entire platform soup-to-nuts and how it fit into our core principles, if at all. In this post we’ll focus on our deployment pipeline, which, to be honest is still a work in progress. Other posts will follow that will dive deeper into software architecture, languages, processes, and platforms. 🙂
What’s the problem, bro?
After much frustration, a few folks on the team decided to take this head on and start capturing lost productivity time and failure reasons over the course of three months. We found that we suffered from a litany of issues ranging from outright failures, levels of technical indirection, and miscommunication losing 1 man-hour on the low end up to 24 man-hours on the high end. And to make matters worse, this was with a single team! Clearly, this wasn’t going to work as we scaled the organization. Especially so with remote onshore and offshore teams.
After further analysis we found that that the root cause for much, but not all, of the pain was a little known, but often used application called the “Deploy App”. Again, it wasn’t the sole cause since it represented a part of the pipeline, albeit a large part of it. So what is it exactly? Well, it delivers code to all environments including production. Sounds simple you’d think.
So how did our pipeline work?
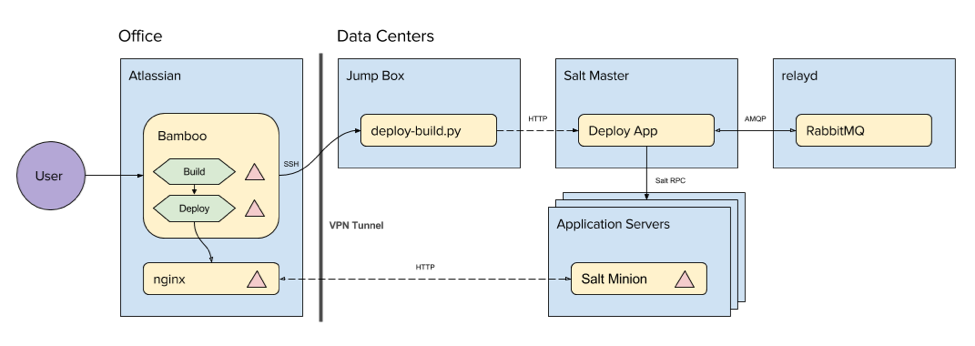
Old Wiredrive Deployment Process
- Trigger build through Bamboo.
- Trigger deploy through Bamboo to trigger Python script on the data center jump box.
- Python script makes an HTTP request to trigger the Deploy App which abstracts Salt.
- Deploy App sends/receives messages to trigger n-Salt minions (aka target servers) to pull TAR file(s) from Bamboo over HTTP.
Don’t reinvent the wheel
It may look like a simple diagram but complexity lurks beneath the surface. First, the Deploy App was nearly a thousand lines of code and not very well maintained. The original developer had moved on a while back and no one had the time (or patience) to take it on. Second, much of what the Deploy App did was to orchestrate and coordinate a sequence of deployment related events which is already well understood by many solution providers including Salt. So why reinvent the wheel? I am paid to build collaboration tools to enable creativity, not to build deployment orchestration applications.
To compound matters, what was reported by the various touch points didn’t coincide with what actually happened. In other words, some things would report failures and be successful, while other times it would report successful and utterly fail. And so begins the Sherlock Holmes sleuth game. Rinse and repeat n-times per each environment.
New Goal, New Deployment Plan
With that, we set our sights on a new goal: reduce the time needed to deploy to < 5 minutes with > 99.9% reliability. To do that, we made the decision to explore new tooling to fulfill this goal with a parallel goal of reducing unnecessary complexity. Ultimately though, the goal is to get to Continuous Delivery which itself is a cultural journey for us. We identified a few interim milestones along that journey:
- Reduce the number of processes and steps needed to deploy code
- Identify a simpler, better adopted automation tool
- Implement widely available continuous delivery tool chains and practices
Ansible is the Answer
Our first plan of attack was to identify a different tool that would ultimately replace the Deploy App and dramatically reduce the amount of code complexity we took on. Here we landed on Ansible which immediately did a couple things. First, it eliminated our single point of failure. Much of the team had used or were familiar with Ansible from previous job experience. Second, we turned what took a 1000+ lines of code complexity and growing into roughly 100 line playbooks. Although standard, these playbooks were independently managed, deployed, and source controlled by independent teams which democratized the deployment tool chain.
Switching gears, we eliminated several steps, processes, and levels of indirection that existed previously.
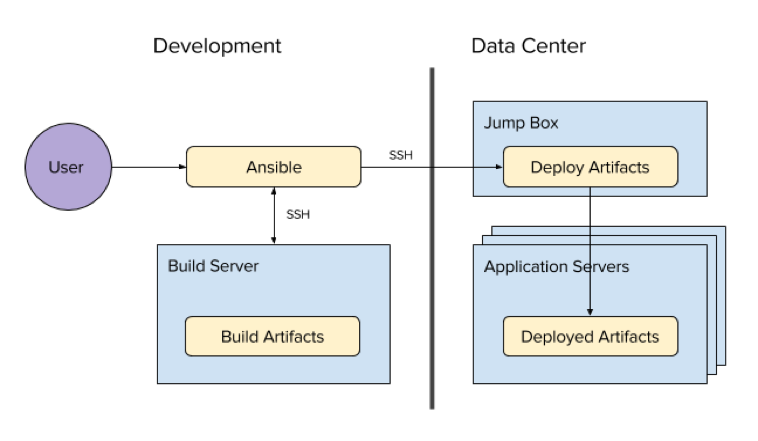
New Wiredrive Deployment Process
As you can likely see from above, we reduced the number process boxes and protocols necessary from AMQP, HTTP, a custom Python script, and RPC to SSH. Furthermore, we had single source of truth which could tell us the state of a particular deployment without having to put our Sherlock Holmes hat on.
For those CI/CD aficionados, yes we are not there yet. We’re missing a few key processes here, namely a continuous integration process. To be clear, that doesn’t mean we aren’t testing. We are simply running our automated tests manually. (I did say this was a journey, didn’t I?) Our next phase is to re-integrate our continuous integration process (with testing) but in a different permutation and with more bells and whistles to ensure our code quality is up to craftsmanship standards. Stay tuned for that blog post!
By Edan Shekar
Tags: deploy
See more from Wiredrive:
Features
MediaSilo and Wiredrive Join Together to Evolve Collaboration
We are pleased to announce that effective immediately, Wiredrive and MediaSilo have joined forces to become the largest platform for creative video collaboration in advertising and media & entertainment.
02.09.2017
Events
5 Blockbuster Ads from the 2016 Super Bowl
Counting down the days until Super Bowl 51: if last year’s commercials are any indication of what’s to come, we’re in for some real popcorn entertainment. At Wiredrive we not only look forward to the big game on Super Bowl Sunday, we also look forward to the biggest commercial showdown of the year. In anticipation
01.27.2017
Customers
Securely managing the collaborative power of a Hollywood giant
Leslie Osborne is the Assistant Manager, Worldwide Creative Content at Paramount Pictures. With a long title and an even longer list of responsibilities, Osborne is at the charge to create and oversee marketing content across some of Paramount’s largest feature films, including Interstellar, Transformers, The Big Short, and more recently, Arrival, Fences, and Silence.



